
Lice i telo štampe
Rodna ravnopravnost, kao osnov razvoja otvorenog, demokratskog i pravednog društva, podrazumeva jednaku zastupljenost, moć i učešće oba pola u svim sferama javnog i privatnog života. Kao rezultat zloupotrebe moći javljaju se različiti oblici diskriminacije (rasne, rodne, seksualne, manjinskih grupa itd), te pojava društvenih nejednakosti i nepravdi.[3] Usled čvrsto ukorenjenog sistema patrijahalnih hijerarhijskih odnosa koji postoje između muškaraca i žena, u svakodnevnom društvenom, profesionalnom i porodičnom okruženju diskriminacija zasnovana na rodu često ostaje skrivena, neprepoznatljiva i nejasna. Ipak, sveprisutni portret rodnih identiteta, uloga i odnosa moći dat je u vidu poruka masovnih medija,[4] za koje se može postaviti pitanje da li promovišu rodnu ravnopravnost ili rodne stereotipe.
Uloga medija, počev od štampe, pa sve do novijih oblika elektronskih medija, u konfigurisanju ponašanja, modifikaciji društvenih normi i konstruisanju društvene realnosti od fundamentalnog je značaja.[5] Medijske reprezentacije utiču na formiranje javnog mnjenja ne samo reflektujući slike stvarnosti, već i reprezentujući i kreirajući interpretacije, čija će značenja nastala u ovom procesu često postati učvršćena u društvu i kulturi u okviru koje postoje.[6] Na taj način, svojom sposobnošću da oslikaju, uspostave ili odbace identitete, kulturne vrednosti i socijalne odnose, mediji služe kao moćno sredstvo u izgradnji društvenih uloga polova i njihovih odnosa.[7] U razmatranju ravnopravnosti polova, osim medijske prisutnosti, bitan je i pojam medijske odsutnosti, koji zajedno omogućavaju uočavanje postojećeg odnosa moći među polovima i stvaranje stereotipa kao dominantnih predstava u nekoj društvenoj zajednici.[8]
O rodnom jazu i stereotipima svedoče različita sprovedena istraživanja koja se bave kritičkom analizom diskursa medijskih sadržaja koji imaju najviše uticaja na auditorijum. Razlike u prikazivanju polova najčešće su praćene kroz propagandni program, odnosno televizijske reklame u kojima se jasno ogleda matrica tradicionalnih rodnih uloga.[9] Ipak, stereotipi muškaraca kao „jačeg pola“, a žena kao „lepše polovine“ oslikavaju se i u radijskim reklamama,[10] informativnom programu nacionalnih televizija,[11] u tekstovima i na fotografijama magazina[12] i novinske štampe.[13] Medijska praznina u pogledu reprezentovanja žena odjekuje stranicama kako svetske tako i srpske štampe i elektronskih medija. Žene su nedovoljno zastupljene u različitim medijima, a i kada su prisutne, prevashodno su oskudno obučene i prikazane u stereotipnim ulogama.[14] Zauzimajući deseti deo medijskog prostora, o ženama se obično govori u rubrikama crne hronike, kulture i estrade,[15] dok su pet do deset puta manje zastupljene u odnosu na muškarce kada su u pitanju ozbiljne političke teme.[16] Iako je u Srbiji stopa aktivnosti žena sa visokim obrazovanjem viša od stope aktivnosti muškaraca istog nivoa obrazovanja (71% odnosno 65%),[17] među autoritetima (stručnjacima, direktorima, predstavnicima kompanija i slično) koji se pozivaju da javno iznesu svoja mišljenja i koji su važni sagovornici na datu temu retko su osobe ženskog pola.[18] Međutim, ne može se reći da je u pitanju bilo kakva zavera novinara protiv žena, već Cvetković ukazuje na činjenicu da je zatečeno stanje zapravo društveni problem kojim se treba baviti. Pozitivnih primera žena u ulogama koje po značaju ne zaostaju od onih dodeljenih muškarcima ipak ima, ali su oni retki i nedovoljno vidljivi.
Tokom poslednjih par decenija Srbija je prošla kroz niz političkih, društvenih i ekonomskih promena, prevashodno važnih za žene i njihove značajno bolje mogućnosti obrazovanja i zapošljavanja. Zakonski osnov za uvođenje i uređivanje rodne ravnopravnosti u Srbiji dat je, pre svega, Ustavom Republike Srbije (usvojenim 2006. godine),[19] kojim se utvrđuje obaveza države da jemči ravnopravnost žena i muškaraca i razvija politiku jednakih mogućnosti. Zakon o ravnopravnosti polova (donet 2009. godine), osim što reguliše oblasti zapošljavanja, zdravstvene zaštite, porodičnih odnosa, obrazovanja, političkog i javnog života, sporta itd, u članu 41 kaže da „Informacije putem sredstava javnog informisanja ne smeju sadržavati niti podsticati diskriminaciju zasnovanu na polu.“[20] O značaju medija, kao jednoj od ključnih oblasti za unapređivanje rodne ravnopravnosti, svedoči i Nacionalna strategija za poboljšanje položaja žena i unapređivanje rodne ravnopravnosti,[21] usvojena februara meseca 2009. godine. Nasuprot navedenim pozitivnim zakonskim regulativama, na pitanje da li je ostvarena ravnopravnost žena u srpskom društvu mogu se čuti različiti odgovori. Neki smatraju da su žene potpuno ravnopravne, neki misle da je već ostvarena ravnopravnost izgubljena, dok ima i onih koji smatraju da je nikad nije ni bilo i da je potrebno još mnogo kako bi se ona postigla. Šta bi u ovom slučaju mogao biti „rog“ koji bi pomogao u dolaženju do nekog verodostojnog odgovora?
S ciljem otkrivanja informacija na osnovu kojih građani formiraju predstavu o rodnoj ravnopravnosti, te i neusaglašenosti stvarnog stanja i rodne ravnopravnosti kojoj težimo, predmet ovog istraživanja biće utvrđivanje mere i uloga kojima su žene zastupljene u srpskoj štampi. Poseban značaj ovoga rada zapravo leži u primenjenoj metodi kojom se na inovativan način omogućava sprovođenje analize sadržaja medijskih tekstova. Imajući u vidu pojavu sve veće količine mašinski čitljivih sadržaja nad kojima se može vršiti analiza, postojanje alata koji omogućava automatsko prepoznavanje i obeležavanje teksta različitim informacijama uticaće na sprovođenje većeg broja efikasnijih i jeftinijih istraživanja. Različiti alati u vidu programa namenjenih obradi prirodnih jezika su se pre više decenija pokazali kao izuzetno korisni na polju empirijskih istraživanja korpusne lingvistike. Međutim, retka su istraživanja koja se bave analizom sadržaja radi utvrđivanja rodne pristrasnosti putem automatskog prepoznavanja karakteristika i uloga polova.[22]
Merenje prisutnosti žena u štampi – korpusni pristup
U ovom radu ćemo koristiti korpusni pristup i metode računarske lingvistike da bismo došli do nekih verodostojnih podataka o zastupljenosti muškaraca i žena u savremenoj srpskoj štampi.
Za naš eksperiment koristićemo više korpusa novinskih tekstova koji će imati različite uloge. Prvi korpus će se sastojati od novinskih tekstova iz dnevne štampe i elektronskih medija objavljenih na internetu. Novinski tekstovi su preuzimani sa zvaničnih stranica Politike, Blica, Večernjih novosti, Danasa i B92 u periodu od 2009-2015, te je taj korpus nazvan 5izvora. S obzirom na to da su za preuzimanje tekstova, njihovu korekciju i sređivanje za dalju obradu bili zaduženi studenati u vidu seminarskih radova,[28] većina tekstova je objavljena februara i marta meseca odgovarajuće godine, u vreme izrade seminarskih radova. Svaki student je bio zadužen za jedan dan u februaru ili martu mesecu, kada je trebalo da preuzme iz ovih pet izvora dva ili tri članka koja su obrađivala temu koja je prema određenom izvoru obeležila taj dan. Preporuka je bila da se preuzimaju duži članci i da se izbegavaju sportske teme. Ovaj korpus je podeljen u sedam potkorpusa, po godinama objavljivanja članaka, pa je tako kasnije i korišćen.
Drugi korpus se sastoji od izvesnog broja članaka objavljenih u dvonedeljniku Bazar.[29] Na naslovnoj stranici ovog časopisa stoji: „Istraživanja su pokazala da ʼBazarʻ čitaju visokoobrazovane žene i one sa srednjom stručnom spremom, koje su uglavnom zaposlene.Takođe, više od jedne petine čitalaca su muškarci. Starosna dob je između 28 i 55 godina, ona koja je i najpoželjnija, jer su ekonomski samostalne. Ispostavilo se da u jednoj porodici čak tri generacije žena čita ʼBazarʻ.“[30] Iz ovoga je jasno da Bazar spada u kategoriju časopisa koja je namenjena pre svega, ako ne i isključivo, ženama. Ovaj korpus je trebalo da bude upravo korpus novinskih članaka iz medija namenjenih pre svega ženama. Trebalo je da bude veći i raznovrsniji, ali to nije ostvareno iz tri razloga. Pre svega, ideja za njegovo prikupljanje je nastala znatno kasnije, a zatim članci iz većine ciljnih časopisa nisu dostupni na internetu ili su dostupni samo manji odlomci („Ilustrovana politika“, „Viva“). Konačno, sadržaj članaka nekih od časopisa iz ove grupe je takav da bi se autori ovog rada, univerzitetski nastavnici, osećali veoma nelagodno da ih uključe u nastavne aktivnosti („Blic žena“, „Gloria“, „Skandal“, „Svet“, itd)
Treći korpus se sastoji od članaka iz nedeljnika Vranjske novine[31] koji su objavljeni na veb prezentaciji ovih novina tokom 2011. i 2012. godine. Ovaj časopis je po orijentaciji na izvestan način sličan novinama i medijima predstavljenim u prvom korpusu jer se takođe bavi „ozbiljnim“ temama, ali se razlikuje po polemičnom tonu, korišćenom jeziku i konačno po tome što se ne objavljuje u prestonici već u manjem provincijskom gradu.
U tabeli I predstavljene su dimenzije ovih korpusa i potkorpusa merene brojem reči i brojem rečenica. Tekstovi su segmentirani na rečenice automatski (videti naredni odeljak), pa date brojeve treba uzeti samo kao približne vrednosti. Merenje veličine korpusa brojem reči je uobičajeno u korpusnoj lingvistici, ali je zbog višeznačnosti pojma „reč“ neophodno precizno odrediti njegovo značenje. Štaviše, da bi se izbegla drugačija tumačenja, umesto pojma „reč“ korpusni lingvisti koriste pomoćne pojmove „token“ i „korpusna reč“.[32] Tokeni se definišu posredno, izborom skupa karaktera čiji se elementi nazivaju graničnici ili separatori. Uobičajeni skup separatora sadrži beline (razmak, tabulator, znak za novi red) i znake interpunkcije. Za potrebe ovog rada svaki karakter koji nije ni slovo ni cifra predstavlja jedan separator. Svaki pojedinačni separator, izuzimajući beline, jeste jedan token. Takođe, svaki neprekidan niz karaktera teksta koji se nalazi između dva separatora i sam ne sadrži separatore predstavlja jedan token. Korpusna reč je posebna vrsta tokena koja se sastoji isključivo od slovnih karaktera. Na primer, ime „Ana-Marija“ se sastoji iz tri tokena („Ana“, „-“ i „Marija“) i dve korpusne reči („Ana“ i „Marija“).
Iz tabele I se vidi da su potkorpusi novinskih vesti neravnomerne veličine, što potiče od varijacije u broju studenata po školskim godinama.
Tabela I
Šta tražimo u korpusu i kako to dobijamo
U prikupljenim korpusima tražićemo pojavljivanja referenci na osobe muškog i ženskog pola preko pojavljivanja njihovih imena. Imena koja tražimo će biti ili puna imena, a pod tim podrazumevamo pojavljivanje bar jednog ličnog imena i bar jednog prezimena, ili pojavljivanje samo prezimena. Dakle, slučajeve u kojima se osobe u tekstu imenuju samo ličnim imenom nećemo uzimati u obzir, osim ako se radi o istaknutim osobama koje su poznate samo pod jednim imenom koje može biti i lično, na primer, pripadnici kraljevskih porodica i crkveni velikodostojnici. Kod punih imena vodićemo računa o promenljivom redosledu ličnog imena i prezimena, o mogućnosti pojavljivanja dva prezimena, srednjeg imena (imena roditelja) ili inicijala, nadimka, profesionalnih titula i sl. Kod korišćenja samo prezimena, vodićemo računa o mogućnosti korišćenja prisvojnog prideva ili imenice izvedenih iz prezimena za osobe ženskog pola.
Uz pojavljivanje imena, bilo punih bilo samo prezimena, tražićemo i naznake funkcija, uloga ili nekih drugih određenja koja objašnjavaju ko je osoba o kojoj se u tekstu govori, a koja se u tekstu pojavljuju pre ili posle imena u obliku imenske fraze. Sva identifikovana imena će u tekstu biti adekvatno obeležena,[33] a uz svako identifikovano ime će stajati naznaka da li ono označava osobu muškog ili ženskog pola, ili naznaka da se pol osobe na koju se ime odnosi na osnovu imena i analiziranog konteksta nije mogao odrediti.
Da bi se ovako postavljen zadatak mogao obaviti korišćene su napredne metode ekstrakcije informacije – podoblasti obrade prirodnih jezika – koje su u našem slučaju podrazumevale korišćenje veoma obimnih elektronskih rečnika srpskog jezika koji sadrže iscrpne informacije (morfološke, derivacione, semantičke i mnoge druge) koje su potrebne za obavljanje ovog zadatka. Ovi rečnici uključuju i veliki broj imena i prezimena koja se koriste u Srbiji, kao i trnaskribovanih stranih imena, pre svega s engleskog govornog područja. Osim rečnika, korišćene su kompleksne gramatike plitkog parsiranja (engl. shallow parsing) koje analizirajući lokalni kontekst potencijalnih imena potvrđuju pretpostavku, određuju granice imena i pridruženih uloga (ako su navedene), kao i pol osobe na koju se ime odnosi. Ove gramatike lokalnog parsiranja su deo obuhvatnijeg sistema za prepoznavanje imenovanih entiteta u tekstovima na srpskom jeziku (engl. named entities – podrazumevaju se svi prosti i višečlani nazivi kojima se prepoznaju jedinstveni entiteti, kao što su osobe, organizacije, lokacije, i sl.). U ovom radu nećemo se baviti opisom korišćenih metoda koje su detaljnije predstavljene u drugim radovima.[34]
Nekoliko navedenih primera ilustruje tražena pojavljivanja imena i način obeležavanja rezultata:[35]
- Puno ime muške osobe:
<pers><role>Britanski ministar spoljnih poslova</role><m.persName.full>Vilijam Hejg</m.persName.full></pers>
- Prezime muške osobe:
...rekao je <pers><m.persName.last>Mali</m.persName.last></pers>
- Puno ime ženske osobe:
<pers><f.persName.full>Gorica Mitić</f.persName.full><role>, bivša direktorka Toplane</role></pers>
- Prezime ženske osobe:
...smatra da <pers><f.persName.last>Markovićeva</f.persName.last></pers> ne bi trebalo da čeka...
- Ime istaknute osobe (čiji pol nije određen):
...izveo državni udar protiv <pers.spec>kralja<x.persName.name POL="M">Idrisa </x.persName.name></pers.spec>...
- Puno ime osobe za koju sistem nije odredio kog je pola:
<pers><role>bivši ministar socijalne politike</role><x.persName.full>Natalija Koroljevska</x.persName.full></pers>
- Prezime osobe za koju sistem nije odredio kog je pola:
<pers><role>Kancelarka</role><x.persName.last>Merkel</x.persName.last></pers> je u Berlinu rekla...
- Ime osobe za koju sistem nije odredio kog je pola:
<pers.spec>papa<x.persName.first>Franja</x.persName.first></pers.spec>
Zašto je potrebna evaluacija i kako je sprovodimo
Nijedan automatizovani sistem za pronalaženje i ekstrakciju informacija nije savršen, to jest među rezultatima koje proizvodi javlja se određen broj grešaka.[36] Rezultati koje sistem proizvodi se ne mogu koristiti ni u kakvim daljim istraživanjima niti za dokazivanje određenih pretpostavki ukoliko se prethodno ne utvrdi stepen i vrsta grešaka. Greške koje se javljaju se obično mogu okarakterisati kao propusti – nije prepoznato nešto što je trebalo, uljezi – prepoznato je nešto što nije trebalo i nepoklapanje – opsezi onoga što je trebalo prepoznati i onoga što je prepoznato se delimično preklapaju ali ne u potpunosti. Izvori grešaka takođe mogu biti različiti i potiču delimično od višeznačnosti oblika u prirodnom jeziku za čije razrešavanje je potrebna analiza šireg konteksta. S tim u vezi, ni model jezika koji se koristi u sistemu za prepoznavanja često nije dovoljno razrađen, a ponekad ni tehnologija na kojoj se sistem zasniva ne dopušta veća poboljšanja. Na primer, gramatike plitkog parsiranja ne mogu da koriste dovoljno širok kontekst da bi sve višeznačnosti bile ispravno razrešene. Konačno, neke greške prepoznavanja potiču od grešaka u samom tekstu (tipografske, pravopisne, sintaksne greške). U nekim slučajevima se ovo i ne smatra greškama, jer zašto bi se od sistema očekivalo da prepozna nešto što je pogrešno zapisano. No, s druge strane, kako čovek ume da prepozna traženo (npr. ime) čak iako su ono ili neke reči u njegovom okruženju pogrešno zapisani, ima smisla da se to očekuje i od automatizovanog sistema.
U našem slučaju izvori grešaka prepoznavanja su svi oni upravo pomenuti. Što se tiče tipova grešaka, oni se u slučaju našeg zadatka mogu, pre svega, ovako odrediti: imamo greške u prepoznavanju imena, greške u prepoznavanju uloge osobe na koju se ime odnosi i greške u prepoznavanju njenog pola. U slučaju prva dva tipa grešaka javljaju se propusti, uljezi, nepoklapanja kao i greške zbog grešaka. U slučaju prepoznavanja pola moguće su tri neželjene situacije: pol je pogrešno određen, pol nije uopšte određen (propust) i ime je označeno i kao muško i kao žensko (kontradikcija).
Sva prepoznavanja imena i pola u celokupnom korpusu 5izvora su proverena, što znači da su u tekst dodavane etikete (kod grešaka propusta), odnosno, da su dodavani atributi s naznakom greške u slučajevima drugih vrsta grešaka. Greške u prepoznavanju uloga osoba ovom prilikom nisu proveravane, jer nisu od prevelikog značaja za ovo istraživanje. Proveru su radili studenti na osnovu iscrpnog uputstva za rad, a njihov rad su kontrolisali nastavnici,[37] tako da se konačan rezultat može smatrati dosta pouzdanim.
Slede primeri korektnog obeležavanja imena, grešaka i njihovog obeležavanja:
- Ime je dobor označeno, a i pol je dobro određen:
<persColl>Srpske teniserke <f.persName.full>Jelena Janković</f.persName.full> i <f.persName.full>Ana Ivanović</f.persName.full></persColl> zadržale su svoje pozicije na najnovijoj WTA listi.
- Ime je dobro obeleženo, ali pol nije uopšte određen. U tom slučaju studenti su dodavali atribut POL sa ispravnom vrednošću pola:
<pers><role>Najbolji pojedinac utakmice,</role><x.persName.full POL=“M“>Sašo Ožbolt</x.persName.full></pers>, imao je priliku da u poslednjem napadu Olimpije...
- Ime je dobro obeleženo, ali pol je pogrešan. I u ovom slučaju dodaje se isti atribut kao i u prethodnom slučaju.
Zasedanje je otvorio predsednik Međunarodnog suda pravde <pers><role>slovački sudija</role><f.persName.full POL="M">Peter Tomka</f.persName.full></pers>.
- Ime je dobro određeno, ali je pol kontradiktoran – ime je dobilo etikete i za muški i za ženski pol. U ovom slučaju se ispravna etiketa zadržava, a u neispravnu se dodaje atribut POL kao i u prethodna dva slučaja. Treba napomenuti da se u procesu prvere ništa od etiketa ne briše, upravo da bi se postignuti rezultati mogli korektno proceniti.
Takođe je podsetio da je <pers><role>hrvatski predsednik</role><m.persName.full><f.persName.full POL=”M”>Ivo Josipović</f.persName.full></m.persName.full></pers> u decembru 2012...
- Pol je dobro određen, ali je ime samo delimično dobro određeno (greška nepoklapanja). U ovom slučaju dodaje se atrubut IME s vrednošću UOK.
Šef civilnog vazduhoplovstva Azharudin <m.persName.full IME="UOK">Abdul Rahman</m.persName.full> je uneo konfuziju...
- Ime je delimično dobro označeno, a ni pol nije dobro određen. U ovom slučaju je potrebno dodavanje oba atributa: IME i POL.
Serena <pers><m.persName.last IME=“UOK“ POL=“F“>Vilijams</m.persName.last></pers> ponovo je postala svetski reket broj jedan.
- Ime je u potpunosti propušteno. U ovom slučaju treba ručno dodati XML etikete s vrednošću MISS atributa IME.
Policija je identifikovala treću osobu kao 21-godišnju <f.persName.full IME="MISS">Rosauru Ernandes-Barios</f.persName.full>
- Označeno je kao ime osobe nešto što to uopšte nije (uljez). U ovom slučaju treba dodati ručno etikete s vrednošću NOK atributa IME.
Prvi reket sveta, koji je bio član reprezentcije koja je osvojila <pers><m.persName.full IME=“NOK“>Dejvis Kup</m.persName.full></pers> 2004. godine, rekao je da jedva čeka meč...
- Došlo je do propusta u obeležavanju zbog greške u samom tekstu. U ovom slučaju treba ručno dodati XML etikete s vrednošću ERR atributa IME.
<m.persName.full IME=“ERR“> Branislav Cevtković</m.persName.full>, direktor fabrike "Tihos"...
Dobijeni rezultati i šta nam oni govore
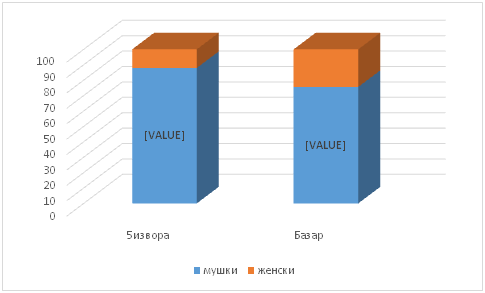
Rezultati prebrojavanja koji su dobijeni na materijalu koji je prošao dvostruku proveru (prvo studenti, zatim nastavnik) pokazuju da se u korpusu 5izvora javlja ukupno 11.177 imena osoba (tipova koji su prethodno opisani), od toga 9.825 (87,9%) imena muškaraca prema 1.352 (24.42%) imena žena. U mnogo manjem korpusu Bazar javlja se ukupno 561 ime, od toga 424 (75,58%) muška prema 137 (24.42%) ženskih imena. Ovi odnosi su vizuelno prikazani na slici I.
Slika I
Tabela II
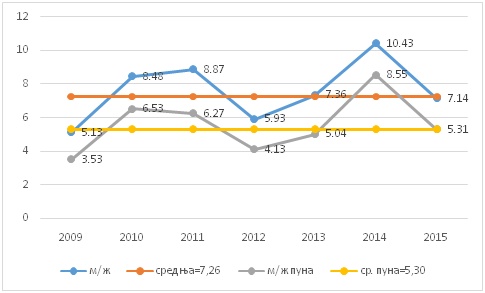
Podaci iz tabele II govore da se prezimena za imenovanje muških osoba koriste u korpusu 5izvora skoro isto toliko kao i puna imena, nešto manje u Bazaru. Takvo imenovanje ženskih osoba je značajno manje u korpusu 5izvora, a retko u Bazaru. S obzirom na to da je prepoznavano samo kod istaknutih ličnosti, korišćenje samo ličnog imena je malo očekivano u svim slučajevima. S toga je odnos punih muških, prema punim ženskim imenima uvek manji, kao što se i vidi na grafikonu na slici II.
Slika II
Odnos muških prema ženskim imenima u raznim godištima korpusa 5izvora je prikazan na slici II. Može se uočiti da ne postoji nikakav trend ni rasta ni opadanja jednih imena u odnosu na druga, premda je dosta upadljivo značajno povećanje učešća muških imena 2014. godine.
U korpusu 5izvora se 2.125 puta pojavljuje ime muške osobe s naznakom uloge, funkcije ili profesije, nasuprot 328 pojavljivanja kod ženskih osoba. Primećuje se da među „top 10“ uloga (funkcija, profesija) muškaraca nema predstavnika, poslanika, profesora i supruga (koje se javljaju kao „top 10“ uloge žena u korpusu), a da među „top 10“ žena nema premijera, lidera, advokata i savetnika. Naš pristup nam je omogućio da utvrdimo za dva „najeminentnija“ zanimanja predsednik i ministar na šta se odnose. U slučaju muškaraca, predsednici su najčešće država (140), političkih partija i sindikata (72), opština (10) i skupštine (16). Među ženama nema predsednika država i opština, jedna je predsednica sindikata, dok je, izgleda, predsednik skupštine omiljena ženska funkcija (22). Među muškarcima ima ministara svih resora – ukupno 23 – dok se žene javljaju kao ministarke u samo 6 resora: energetike, pravde, finansija, spoljnih poslova,[38] zdravlja i trgovine.
Tabela III
Konačno, rezultati koje smo dobili nam omogućavaju da utvrdimo koji se muškarci i žene najčešće pominju u korpusu 5izvora i rezultati su predstavljeni u tabeli IV. Prilikom računanja broja pojavljivanja osoba u korpusu spojena su pojavljivanja punih imena i prezimena što unosi određenu nepreciznost, jer izdvojena iz konteksta prezimena mogu označavati i druge osobe (u tabeli je označeno koja prezimena nose tu opasnost). Dodatna provera je pokazala da samo prezimena Nikolić i Janković nose realnu opasnost, jer se osim osoba navedenih u tabeli još dosta njih s istim prezimenima pojavljuje u korpusu.[39]
Tabela IV
Rezultati iz Tabele IV nam govore da ne samo da su žene uopšte manje prisutne u štampi od muškaraca, već i kada se gledaju pojedinačno najistaknutijih šest muških i ženskih osoba vidimo da je poredeći po rangu zastupljenost muške osobe 4 (Vučić prema Ešton i Putin prema Barać) do 6 puta veća (Dačić prema Mihajlović).
Kada je reč o jeziku, rezultati iz Tabele III takođe pokazuju da je u sve češćoj upotrebi rodno senzitivan način oslovljavanja, odnosno da se kod navođenja funkcija i uloga ženskih osoba češće koriste imenice ženskog roda (dobijene mocijom roda) od imenica muškog roda – izuzetak je jedino par portparol/portparolka. Kada se ovo uporedi s prisutnošću žena u novinama, bilo ukupno bilo pojedinačno, izgleda da korišćenje naziva funkcija ženskog roda nije u korelaciji sa pažnjom koju ženama posvećuje štampa, iako se u praksi u oslovljavanju žena zaista sve više koristi rodno senzitivan jezik.[40]
Koliko je dobar naš pristup?
Kod korišćenja bilo kog automatizovanog sistema za pronalaženje i ekstrakciju informacija veoma je bitno da se zna koliko je taj sistem dobar. Da bi se to utvrdilo mora se obaviti njegova evaluacija. To se može uraditi bilo korišćenjem takozvanog zlatnog standarda (engl. gold standard) gde se rad sistema upoređuje sa unapred poznatim pozitivnim rezultatom (koji je ranije utvrđen), bilo ručnom proverom rada sistema na nekom manjem uzorku. U nedostatku zlatnog standarda za srpski jezik, mi smo ovog puta primenili drugi pristup, pri čemu su manji uzorci korpusi 5izvora i Bazar.[41]
Da bi se utvrdio kvalitet sistema za pronalaženje i ekstrakciju informacija treba, pre svega, utvrditi šta se od njega očekuje. Zdrav razum nam govori da korisnik od jednog takvog sistema očekuje da dobije što je moguće više informacija koje traži (ako je moguće sve), a takođe očekuje da među informacijama koje je dobio bude što manje onih koje nije tražio (ako je moguće, da ih uopšte nema). Ovako postavljen zadatak nam govori da ništa ne znači podatak da je sistem pronašao, recimo, 1.000 odgovora na traženu informaciju ako se u kolekciji koja se pretražuje nalazi 100.000 korisnih informacija, ili ako je među tih 1.000 zapravo 999 nerelevantnih. U informatičkom okruženju uvek je poželjno da se procena kvaliteta sistema izrazi jednim brojem ili s nekoliko brojeva, jer to olakšava poređenje različitih sistema. Standardne mere koje se već dugi niz godina koriste za procenu sistema za pronalaženje i ekstrakciju informacija su odziv (R), koji predstavlja odnos ukupno pronađenih relevantnih informacija prema ukupnom broju relevantnih informacija i preciznost (P) koja predstavlja odnos ukupno pronađenih relevantnih informacija prema ukupnom broju pronađenih informacija. Ove dve mere se svode na jednu zajedničku meru () koja je harmonijska sredina odziva i preciznosti i koja uvek daje prednost manjoj od njih. Korišćenje F1 mere za poređenje dva ili više sistema onemogućava favorizivanje bilo odziva bilo preciznosti.
U našem slučaju, razdvojili smo tačnost prepoznavanja imena, muških i ženskih, nezavisno od toga da li je sistem pravilno (i da li je uopšte) utvrdio kog je pola osoba koja to ime nosi, i tačnost prepoznavanja pola osobe za imena koja su tačno ili delimično tačno prepoznata. U slučaju prepoznavanja imena, preciznost i odziv smo računali pod sledećim pretpostavkama:
- relevantne pronađene informacije (RelPro)su potpuno tačno prepoznata imena i imena kod kojih ima grešaka nepoklapanja (IME="UOK");
- sve relevantne informacije (TotRel) su potpuno tačno prepoznata imena, imena kod kojih ima grešaka nepoklapanja (IME="UOK") i imena koja su propuštena u prepoznavanju (IME="MISS");
- sve pronađene informacije (TotPro) su potpuno tačno prepoznata imena, imena kod kojih ima grešaka nepoklapanja (IME="UOK") i pogrešna prepoznavanja (uljezi) (IME="NOK").
Odziv se prema tome računa kao , a preciznost kao .
Tabela V
Rezultati u tabeli V pokazuju da je uspešnost našeg sistema u prepoznavanju imena veoma dobra (F1=0,900). Preciznost je, može se reći, izuzetna (P=0,981-0,992), to jest, takoreći sve što je prepoznato su zaista imena. Primećuje se da je prepoznavanje samo imena i samo prezimena značajno lošije od prepoznavanja punih imena, što je logično, jer je kontekst prepoznavanja uži. Takođe, preciznost prepoznavanja ženskih imena je veća, ali je odziv manji (posebno samo za prezimena i imena). U budućnosti treba raditi na poboljšanju sistema u odnosu na ove uočene nedostatke.
U slučaju prepoznavanja pola osoba, računali smo samo odnos tačno prepoznatog pola kod imena koja su tačno prepoznata i imena kod kojih ima grešaka nepoklapanja (IME="UOK");
Tabela VI
Rezultati u tabeli VI pokazuju da je uspešnost prepoznavanja pola kod uspešno prepoznatih imena izuzetno visoka kada su muška imena u pitanju (88,82%), nešto niža kod ženskih imena (75,40%). Uočava se takođe da je uspešnost prepoznavanja punih imena dobra i skoro ista kod muških i ženskih imena (83,35% naspram 84,60%). Dok je prepoznavanje pola kod navođenja samo prezimena izuzetno uspešno kada su u pitanju osobe muškog pola (97,11%), za osobe ženskog pola uspešnost prepoznavanja je svega 46,99%. Prepoznavanje pola kod navođenja samo imena je loše bez obzira na pol, ali su ova pojavljivanja relativno retka u analiziranom korusu pa je njihov uticaj na ukupne rezultate mali.
U tabeli V se uočava još jedna zanimljivost. Osobe muškog pola se mnogo češće imenuju samo prezimenom ili samo imenom (45,39% od ukupnog broja imena muških osoba) nego osobe ženskog pola (24,24% od od ukupnog broja imena ženskih osoba).
Rezultate ove evaluacije možemo upotrebiti za procenu pojavljivanja ženskih imena u proizvoljnom novinskom tekstu.[42] U Vranjskim je automatski prepoznato 18.317 imena:
- muških imena 16.554 (90,38%), od toga
- punih 7.866 (47,52%)
- prezimena 8.688 (52,48%)
- ženskih imena 1.763 (9,62%)
- punih 1.664 (94,38%)
- prezimena 99 (5,62%)
Na osnovu prepoznavanja prezimena ne bi trebalo izvoditi nikakve zaključke, jer su rezulati evaluacije pokazali da prepoznavanje pola osobe imenovane samo prezimenom nije uspešno. Međutim, prepoznavanje pola kod imenovanja punim imenom možemo uzeti kao uspešno. Dobijeni odnos muških prema ženskim punim imenima 4,72 se uklapa u rezultate dobijene na korpusu 5izvora (odnos 5,30, videti sliku II).
I štampa je muškog roda
Šta nam je rog saopštio ovom prilikom?
Rezultati ovog istraživanja o medijskom predstavljanju žena u srpskoj štampi i elektronskim medijima nedvosmisleno nas navode na činjenicu da je ozbiljna štampa i dalje muškog roda. Dokumentovana neravnopravnost polova u medijskim reprezentacijama je zaista upadljiva i omogućava nam identifikovanje obrazaca koji leže u osnovi kulturno i društveno usvojenih stavova, što u prvi plan stavlja problem koji je potrebno rešavati – konstatna izloženost velikog auditorijuma sadržajima koje karakteriše relativna odsutnost žena. Čini se da, imajući u vidu učestalost i kontekst pojavljivanja žena u srpskoj štampi, savremeni medijski svet zapravo mnogo više liči na realnost Srbije s polovine prošlog veka.[43]
U interpretaciji podataka dobijenih ovim istraživanjem, potrebno je imati na umu da analizom nije obuhvaćena sva postojeća srpska štampa, i da u tom smislu ovi rezultati ne mogu biti posmatrani kao kompletan odraz značenja i konačan sud o rodnoj (ne)ravnopravnosti u Srbiji. Ipak, s druge strane, ovo istraživanje, osim što jasno ukazuje na postojanje problema, obezbeđuje osnovu za dalji rad usmeren na njegovo rešavanje. U tom pravcu, kako bi se omogućilo sprovođenje dublje kvalitativne analize medijskih sadržaja, u okviru budućih istraživanja trebalo bi uzeti u obzir širi kontekst reprezentacije žena. S obzirom na to da je istaknutost u novinama indikovana dužinom članka, pojavljivanjem na neparnim stranama i u gornjem delu strane, bilo bi korisno posmatrati učestalost pojavljivanja žena i u odnosu na veličinu članaka i delove u kojima se one pominju. Osim toga, pol autora novinskih članaka takođe može uticati na značenje dobijene slike rodne zastupljenosti. Radi sticanja kompletnije slike, poželjno bi bilo da se automatsko prepoznavanje osoba vrši, ne samo na osnovu ličnih imena koja se pominju u tekstu, već i na osnovu svih onih izraza koji ukazuju na neku osobu ili njenu ulogu.
Prilozi
|
Korpus |
broj rečenica |
broj reči |
|
5izvora-2009 |
3,010 |
61,754 |
|
5izvora-2010 |
1,697 |
45,124 |
|
5izvora-2011 |
1,174 |
29,943 |
|
5izvora-2012 |
2,631 |
65,155 |
|
5izvora-2013 |
2,835 |
72,954 |
|
5izvora-2014 |
4,559 |
117,890 |
|
5izvora-2015 |
876 |
21,807 |
|
5izvora-ukupno |
16,782 |
414,627 |
|
Bazar |
2.773 |
47,410 |
|
Vranjske |
39,096 |
782,304 |
Tabela I. Veličine korpusa korišćenih u istraživanju
|
korpus |
muška imena |
ženska imena |
||||||
|
|
puna |
prezime |
ime |
ukupno |
puna |
prezime |
ime |
ukupno |
|
5izvora |
5.012 |
4.691 |
122 |
9825 |
945 |
399 |
9 |
1352 |
|
% |
51,01 |
47,45 |
1,24 |
100,00 |
69,90 |
29,51 |
0,67 |
100,00 |
|
Bazar |
234 |
165 |
25 |
424 |
115 |
11 |
11 |
137 |
|
% |
55,19 |
38,91 |
5,90 |
100,00 |
83,94 |
8,03 |
8,03 |
100,00 |
Tabela II. Učešće tipova imena u korpusima 5izvora i Bazar
|
Muške osobe |
Ženske osobe |
|||||
|
br. |
uloga |
frek. |
uloga |
ž-frek. |
m-frek. |
frek. |
|
1 |
predsednik |
519 |
predsednica |
42 |
4 |
46 |
|
2 |
ministar |
261 |
predstavnica |
27 |
8 |
35 |
|
3 |
premijer |
185 |
ministarka |
25 |
7 |
32 |
|
4 |
direktor |
143 |
portparolka |
9 |
15 |
24 |
|
5 |
potpredsednik |
131 |
potpredsednica |
21 |
1 |
22 |
|
6 |
lider |
74 |
direktorka |
15 |
6 |
21 |
|
7 |
sekretar |
63 |
kancelarka |
13 |
0 |
13 |
|
8 |
advokat |
37 |
sekretarka |
8 |
5 |
13 |
|
9 |
savetnik |
29 |
poslanica |
10 |
2 |
12 |
|
10 |
portparol |
23 |
profesorka |
7 |
0 |
7 |
|
|
|
|
supruga |
7 |
0 |
7 |
Tabela III. „Top 10“ uloga (funkcija ili profesija) muškaraca i žena u korpusu 5izvora. Kod žena, u koloni ž-frek. data je učestalost pojavljivanja uloge kao imenice ženskog roda, a u koloni m-frek. učestalost pojavljivanja uloge kao imenice muškog roda.
|
osoba |
frek. |
osoba |
frek. |
|
Aleksandar Vučić* |
330 |
Ketrin Ešton |
83 |
|
Ivica Dačić |
258 |
Zorana Mihajlović |
43 |
|
Boris Tadić* |
235 |
Jelena Janković* |
42 |
|
Tomislav Nikolić* |
208 |
Slavica Đukić-Dejanović |
37 |
|
Vladimir Putin |
145 |
Verica Barać |
36 |
|
Darko Šarić* |
135 |
Verica Kalanović |
28 |
Tabela IV. „Top 6“ osoba u korpusu 5izvora. Zvezdicom su označene osobe čija prezimena nose neke druge osobe koje se takođe javljaju u korpusu.
|
5izvora |
muška imena |
ženska imena |
||||||
|
puna |
prez. |
ime |
ukupno |
puna |
prez. |
ime |
ukupno |
|
|
TotPro |
4780 |
4024 |
82 |
8886 |
847 |
272 |
4 |
1123 |
|
RelPro |
4762 |
3877 |
81 |
8720 |
844 |
266 |
4 |
1114 |
|
TotRel |
5012 |
4691 |
122 |
9825 |
945 |
399 |
9 |
1353 |
|
P |
0,996 |
0,963 |
0,988 |
0,981 |
0,996 |
0,978 |
1,000 |
0,992 |
|
R |
0,950 |
0,826 |
0,664 |
0,888 |
0,893 |
0,667 |
0,444 |
0,823 |
|
F1 |
0,973 |
0,890 |
0,794 |
0,932 |
0,942 |
0,793 |
0,615 |
0,900 |
Tabela V. Uspešnost prepoznavanja muških i ženskih imena.
|
5izvora |
muška imena |
ženska imena |
||||||
|
|
puna |
prezime |
ime |
ukupno |
puna |
prezime |
ime |
ukupno |
|
Pol OK |
3969 |
3765 |
11 |
7745 |
714 |
125 |
1 |
840 |
|
% |
83,35 |
97,11 |
13,58 |
88,82 |
84,60 |
46,99 |
25,00 |
75,40 |
|
Pol promenjen |
71 |
4 |
0 |
75 |
34 |
132 |
0 |
166 |
|
% |
1,49 |
0,10 |
0,00 |
0,86 |
4,03 |
49,62 |
0,00 |
14,90 |
|
Pol nepoznat |
722 |
108 |
70 |
900 |
96 |
9 |
3 |
108 |
|
% |
15,16 |
2,79 |
86,42 |
10,32 |
11,37 |
3,38 |
75,00 |
9,69 |
|
Ukupno |
4762 |
3877 |
81 |
8720 |
844 |
266 |
4 |
1114 |
Tabela VI. Uspešnost prepoznavanja pola imenovane osobe.
Slika I. Učešće muških i ženskih imena u dva korpusa
Slika II. Odnos broja svih muških prema broju svih ženskih imena u korpusu 5izvora (m/ž) i odnos punih muških imena prema punim ženskim imenima u istom korpusu (m/ž puna)
[1] Rezultati predstavljeni u ovom radu delom su nastali u okviru istraživanja na projektu 178006 „Srpski jezik i njegovi resursi: teorija, opis i primene“ koji finansira Ministarstvo prosvete, nauke i tehnološkog razvoja Republike Srbije.
[2] Rezultati predstavljeni u ovom radu delom su nastali u okviru istraživanja na projektu 178006 „Srpski jezik i njegovi resursi: teorija, opis i primene“ koji finansira Ministarstvo prosvete, nauke i tehnološkog razvoja Republike Srbije.
[3] Teun A. van Dijk, Discourse and power (Houndmills, Basingstoke, Hampshire: Palgrave Macmillan, 2008), 19-20.
[4] K. Bussey i A. Bandura, „Social Cognitive Theory of Gender Development and Functioning“, u The psychology of gender, ur. Alice H. Eagly, Beall Anne E. i Sternberg Robert J. (New York: Guilford, 2004), 95.
[5] M.P. Matud, C. Rodríguez i I. Espinos, „Gender in Spanish daily newspapers“, Sex Roles 64 (2011), 253.
[6] S. Redman i J. Taylor, „Legitimate family violence as represented in print media: Textual analysis“, Journal of Advanced Nursing 56 (2006), 163. G.B. Cunningham i dr., „Gender representation in the NCAA News. Is the glass half full or half empty?“, Sex Roles 50 (2004), 861. P.J. Shoemaker i S.D. Reese, Mediating the message: Theories of influences in mass media content (New York: Longman, 1996), 30. Smiljana Milinkov, „Kako prići ženi u radijskom etru Srbije? Pokušaj formatiranja novosadskog Radija 021“, u Verodostojnost medija : dometi medijske tranzicije, ur. Rade Veljanovski. (Beograd: Fakultet političkih nauka: Čigoja štampa, 2011), 201. Snježana Milivojević, „Žene i mediji: strategije isključivanja“, Genero posebno izdanje (2004), 14.
[7] Dragana Cvetković, „Vest je muškog roda - etički aspekti rodne ravnopravnosti u informativnom programu nacionalnih televizija u Srbiji“, Kultura 127 (2010), 157.
[8] Ibid.
[9] A.N. Arima, „Gender stereotypes in Japanese television advertisements“, Sex Roles 49 (2003): 89. D.L. Ganahl, T.J. Prensen i S.B. Netzley, „A content analysis of prime time commercials: A contextual framework of gender representation“, Sex Roles 49 (2003), 550. K. Kim i D.T. Lowry, „Television commercials as a lagging social indicator: Gender role stereotypes in Korean television advertising“, Sex Roles, 53 (2005), 908. N. Uray i S. Burnaz, „An analysis of the portrayal of gender roles in Turkish television advertisement“, Gender Roles, 48 (2003), 86. F. Valls-Fernández i J.M. Martínez-Vicente, „Gender stereotypes in Spanish television commercials“, Sex Roles 56 (2007), 697.
[10] A. Furnham i L. Thomson, „Gender role stereotyping in advertisements of two British radio stations“, Sex Roles 40 (1999), 163.
[11] D. Cvetković, nav. rad, 173.
[12] R. Hovland i dr., „Gender role portrayals in American and Korean advertisements“, Sex Roles 53 (2005), 897. T. Mastin i dr., „Product purchase decision-making behavior and gender role stereotypes: A content analysis of advertisements in Essence and Ladies’ Home Journal, 1990–1999“, The Howard Journal of Communication 15 (2004), 229.
[13] M. Len-Ríos i dr., „Representation of women in news and photos: Comparing content to perceptions“, The Journal of Communication 55 (2005), 165. S. Rodgers i dr., „Stereotypical portrayals of emotionality in news photos“, Mass Communication & Society 10 (2007), 138. Zorica Mršević, „Žene u medijima: 2010 u Srbiji“, Genero 12 (2008), 80. S. Milivojević, nav. rad, 17. Smiljana Milinkov, „Siromaštvo žena - medijska isključenost“, Godišnjak Filozofskog fakulteta u Novom Sadu 37-I (2013), 315. Jelena Višnjić, „‘Killing me softly’: izveštavanje štampanih medija o ženama žrtvama nasilja“, Genero 16 (2012), 143. D. Cvetković, nav. rad, 173. M.P. Matud, nav. rad, 262.
[14] R.M. de Cabo i dr., „Perpetuating gender inequality via the internet? An analysis of women’s presence in Spanish online newspapers“, Sex Roles 70 (2014), 69.
[15] S. Milivojević, nav. rad, 15-18.
[16] D. Cvetković, nav. rad, 164.
[17] Tamara Vračarević, prev., Žene i muškarci u Republici Srbiji (Beograd: Republički zavod za statistiku, 2014), 59.
[18] D. Cvetković, nav. rad, 170.
[19] Ustav Republike Srbije, čl. 15.
[20] Zakon o ravnopravnosti polova („Sl. glasnik RS“, br. 104/2009), čl. 41.
[21] Nacionalna strategija za poboljšanje položaja žena i unapređivanje rodne ravnopravnosti („Sl. glasnik RS“, br. 15/2009), 4.6. Uklanjanje rodnih stereotipa u sredstvima javnog informisanja i promocija rodne ravnopravnosti.
[22] R.M. de Cabo, nav. rad, 58.
[23] Politika novine i magazini, „Politika,“ 2015, http://politika.rs/ .
[24] Ringier Axel Springer d.o.o., „Blic,“ 2015, http://www.blic.rs/.
[25] Kompanija Novosti, „Večernje novosti,” 2015, http://www.novosti.rs/.
[26] DAN GRAF d.o.o., „Danas,“ 2015, http://www.danas.rs/.
[27] B92 a.d., „B92.net,“ 2015, http://www.b92.net/.
[28] Ovaj zadatak su obavljali studenti redovnih studija Filološkog fakulteta, grupe za Bibliotekarstvo i informatiku u okviru predmeta Informatički praktikum IV. Zadatak studenata bio je da preuzete tekstove koriguju, jer tekstovi objavljeni na internet prezentacijama odabranih medija obiluju greškama, a da ih potom prevedu u validne XML dokumente.
[29] Politika a.d., „Bazar“, 2015, http://www.bazar.co.rs/.
[30] Politika a.d., „Bazar“, 2015, http://politika-ad.com/cir/strane/bazar.
[31] NIP „Vranjske“ DOO, „Vranjske,“ 2015, http://www.vranjske.co.rs/.
[32] Graeme D. Kennedy, An introduction to corpus linguistics (London: Longman, 1998), 206-207.
[33] Za obeležavanje je korišćen XML jezik; svako ime, kao i uloge osobe na koje se ime odnosi su okruženi početnom i završnom etiketom, što se vidi iz datih primera.
[34] Sandra Gucul-Milojević, „Vlastita imena u ekstrakciji informacija“, INFOteka 11 (2010), 47-58. Sandra Gucul-Milojević, Vanja Radulović i Cvetana Krstev, “A View on the Representation of Women in Serbian Newspaper Texts”, u Application of Finite-State Language Processing: Selected Papers from the 2008 International Nooj Conference, ur. Tamás Váradi, Judit Kuti i Max Silberztein (Newcastle upon Tyne: Cambridge Scholars Publishing, 2010),160-170. Cvetana Krstev i dr, “A system for named entity recognition based on local grammars”, J Logic Computation 24 (2014), 473-489.
[35] Svi tekstovi u svim korišćenim korpusima su zapisani latiničnim pismom, nezavisno od toga kojim pismom su tekstovi bili štampani i prikazani na veb prezentacijama. Stoga će i svi primeri biti zapisani latiničnim pismom. Treba napomenuti da bi sve podjednako funkcionisalo i da je korišćeno ćirilično pismo.
[36] Uostalom, ako bi isti posao radili ljudi i oni bi takođe napravili određen broj grešaka, posebno ako im zadaci nisu dovoljno dobro definisani ili se radi o dosadnom poslu u kome se stalno ponavljaju slični zadaci. Ko od njih pravi veći broj grešaka zavisi od ugla gledanja: neki smatraju da „mašina nikad ne greši“ dok drugi veruju da „mašina ne može da nadmaši čoveka“. U svakom slučaju, automatski se mnogi zadaci, kao i ovaj koji se sastoji od obeležavanja imena, mogu neuporedivo brže uraditi.
[37] Ovaj zadatak su obavili studenti redovnih studija Filološkog fakulteta, grupe za Bibliotekarstvo i informatiku u okviru predmeta Pronalaženje informacija školske 2014/15. godine. U okviru ovog predmeta studenti se upoznaju sa raznim metodama koje se primenjuju u sistemima za pronalaženje i ekstrakciju informacija, pa se kroz ovaj praktičan zadatak mogu najbolje upoznati sa njihovim dometima. Kontrolu rada studenata je obavila Milena Milinković, student doktorskih studija na Filološkom fakultetu.
[38] Odnosi se na Republiku Hrvatsku.
[39] Zanimljivo je napomenuti da se među tim drugim osobama s istim prezimenom dosta često javljaju bliski rođaci osoba iz tabele IV.
[40] D. Cvetković, nav. rad, 174.
[41] Evaluirani korpusi 5izvora i Bazar, eventualno još jednom provereni, moći će se koristiti u budućnosti kao zlatni standard za neke druge sisteme.
[42] Pretpostavljamo da je novi, nepoznati tekst dovoljno sličan po sadržaju i načinu pisanja sa korpusom na kome je vršena evaluacija da se rezultati mogu porediti.
[43] Miloš Macura (ur.), Statistički godišnjak NR Srbije za 1952. god. Godina IV (Beograd: Zavod za statistiku i evidenciju NR Srbije, 1953), 175-176. Udeo žena u radnoj snazi Srbije je 1952. godine iznosio samo 19% što je veoma blisko udelu žena u savremenim srpskim medijima.